R语言数据分析实战:数据结构(1)
一、数据集的概念
数据集通常是由数据构成的一个矩形数组,行表示观测,列表示变量。表2-1提供了一个假想的病例数据集。

不同的行业对于数据集的行和列叫法不同。统计学家称它们为观测(observation)和变量(variable),数据库分析师则称其为记录(record)和字段(field),数据挖掘/机器学习学科的研究者则把它们叫做示例(example)和属性(attribute)。
你可以清楚地看到此数据集的结构(本例中是一个矩形数组)以及其中包含的内容和数据类型。在表2-1所示的数据集中,PatientID是行/实例标识符,AdmDate是日期型变量,Age是连续型变量,Diabetes是名义型变量,Status是有序型变量。
R语言中有许多用于存储数据的结构,包括标量、向量、数组、数据框和列表。表2-1实际上对应着R中的一个数据框。多样化的数据结构赋予了R极其灵活的数据处理能力。
R可以处理的数据类型(模式)包括数值型、字符型、逻辑型(TRUE/FALSE)、复数型(虚数)和原生型(字节)。在R语言中,PatientID、AdmDate和Age将为数值型变量,而Diabetes和Status则为字符型变量。另外,你需要分别告诉R:PatientID是实例标识符,AdmDate含有日期数据,Diabetes和Status分别是名义型和有序型变量。R将实例标识符称为rownames(行名),将类别型(包括名义型和有序型)变量称为因子(factors)。我们会在下一节中讲解这些内容,并在第3章中介绍日期型数据的处理。
二、数据结构
R拥有许多用于存储数据的对象类型,包括标量、向量、矩阵、数组、数据框和列表。它们在存储数据的类型、创建方式、结构复杂度,以及用于定位和访问其中个别元素的标记等方面均有所不同。图2-1给出了这些数据结构的一个示意图。

让我们从向量开始,逐个探究每一种数据结构。
一些定义
R语言中有一些术语较为独特,可能会对新用户造成困扰。在R中,对象(object)是指可以赋值给变量的任何事物,包括常量、数据结构、函数,甚至图形。对象都拥有某种模式,描述了此对象是如何存储的,以及某个类,像print这样的泛型函数表明如何处理此对象。
与其他标准统计软件(如SAS、SPSS和Stata)中的数据集类似,数据框(data frame)是R中用于存储数据的一种结构:列表示变量,行表示观测。在同一个数据框中可以存储不同类型(如数值型、字符型)的变量。数据框将是你用来存储数据集的主要数据结构。
因子(factor)是名义型变量或有序型变量。它们在R中被特殊地存储和处理。
1、向量
向量是用于存储数值型、字符型或逻辑型数据的一维数组。执行组合功能的函数c()可用来创建向量。各类向量如下例所示:
-
a <- c(1, 2, 5, 3, 6, -2, 4)
-
b <- c("one", "two", "three")
-
c <- c(TRUE, TRUE, TRUE, FALSE, TRUE, FALSE)
这里,a是数值型向量,b是字符型向量,而c是逻辑型向量。注意,单个向量中的数据必须拥有相同的类型或模式(数值型、字符型或逻辑型)。同一向量中无法混杂不同模式的数据。
注意:标量是只含一个元素的向量,例如f <- 3、g <- "US"和h <- TRUE。它们用于保存常量。
通过在方括号中给定元素所处位置的数值,我们可以访问向量中的元素。例如,a[c(2, 4)]用于访问向量a中的第二个和第四个元素。更多示例如下:
-
a <- c(1, 2, 5, 3, 6, -2, 4)
-
> a[3]
-
[1] 5
-
> a[c(1, 3, 5)]
-
[1] 1 5 6
-
> a[2:6]
-
[1] 2 5 3 6 -2
最后一个语句中使用的冒号用于生成一个数值序列。例如,a <- c(2:6)等价于a <- c(2,3, 4, 5, 6)。
2、矩阵
矩阵是一个二维数组,只是每个元素都拥有相同的模式(数值型、字符型或逻辑型)。可通过函数matrix创建矩阵。一般使用格式为:
-
myymatrix <- matrix(vector, nrow=number_of_rows, ncol=number_of_columns,
-
byrow=logical_value, dimnames=list(
-
char_vector_rownames, char_vector_colnames))
其中vector包含了矩阵的元素,nrow和ncol用以指定行和列的维数,dimnames包含了可选的、以字符型向量表示的行名和列名。选项byrow则表明矩阵应当按行填充(byrow=TRUE)还是按列填充(byrow=FALSE),默认情况下按列填充。代码清单2-1中的代码演示了matrix函数的用法。
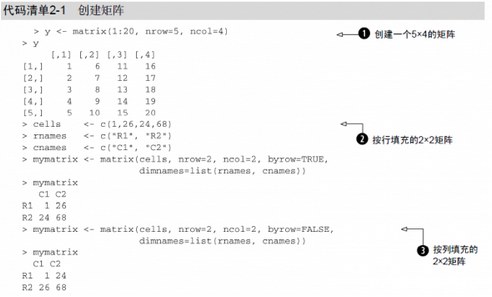
我们首先创建了一个5×4的矩阵①,接着创建了一个2×2的含列名标签的矩阵,并按行进行填充②,最后创建了一个2×2的矩阵并按列进行了填充③。我们可以使用下标和方括号来选择矩阵中的行、列或元素。X[i,]指矩阵X中的第i
行,X[,j]指第j 列,X[i, j]指第i 行第j 个元素。选择多行或多列时,下标i 和j 可为数值型向量,如代码清单2-2所示。

首先,我们创建了一个内容为数字1到10的2×5矩阵。默认情况下,矩阵按列填充。然后,我们分别选择了第二行和第二列的元素。接着,又选择了第一行第四列的元素。最后选择了位于第一行第四、第五列的元素。
矩阵都是二维的,和向量类似,矩阵中也仅能包含一种数据类型。当维度超过2时,不妨使用数组。当有多种模式的数据时,不妨使用数据框。
3、数组
数组(array)与矩阵类似,但是维度可以大于2。数组可通过array函数创建,形式如下:其中vector包含了数组中的数据,dimensions是一个数值型向量,给出了各个维度下标的最大值,而dimnames是可选的、各维度名称标签的列表。代码清单2-3给出了一个创建三维(2×3×4)数值型数组的示例。

如你所见,数组是矩阵的一个自然推广。它们在编写新的统计方法时可能很有用。像矩阵一样,数组中的数据也只能拥有一种模式。
从数组中选取元素的方式与矩阵相同。上例中,元素z[1,2,3]为15。
华体会hth登录入口最新版考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;










 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330